Salve galerinhaaaa, Tudo certo com vocês?
Existe uma categoria de problema que não aparece nos relatórios de bug, não gera alertas de monitoramento e raramente entra no backlog de uma sprint. Mesmo assim, ele cresce a cada novo deploy, a cada tabela que ganha mais registros, a cada pico de acesso que o sistema mal sobrevive.
Estamos falando de débito técnico de performance — e três padrões são responsáveis pela maior parte dos casos que vejo em aplicações Laravel em produção: queries N+1, complexidade O(n²) e recursividade desnecessária.
O que é débito técnico de performance?
Débito técnico, no sentido clássico, é o custo futuro gerado por decisões técnicas tomadas no presente por conveniência, pressa ou falta de contexto. O débito de performance é uma variante específica: código que funciona corretamente, mas que escala de forma ruim.
O problema é que ele costuma passar despercebido por muito tempo. O sistema que foi construído para 500 usuários simultâneos não foi projetado para 50.000 — e ninguém revisou o que foi escrito naquela época.
A pergunta que vale fazer periodicamente à sua equipe é: “esse código ainda faz sentido para o volume de dados que temos hoje?”
1. Queries N+1: o mais comum e o mais subestimado
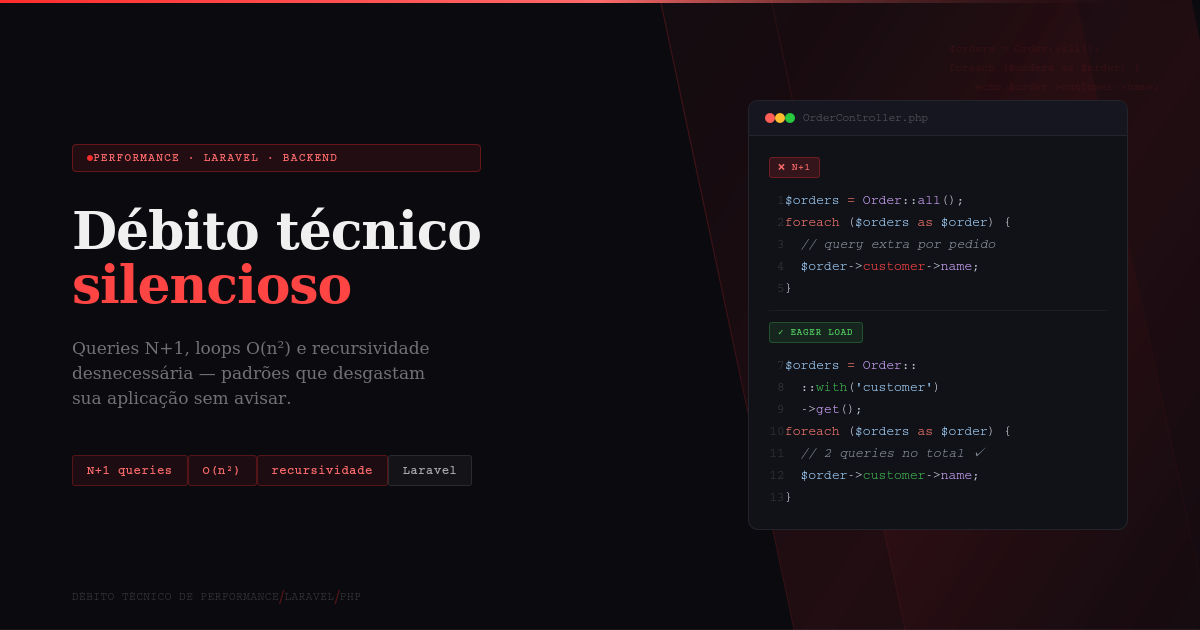
A query N+1 acontece quando o código executa uma consulta para buscar uma lista de registros e, em seguida, dispara uma nova query para cada item dessa lista individualmente. O nome vem exatamente disso: 1 query inicial + N queries para os detalhes.
$orders = Order::all();
foreach ($orders as $order) {
echo $order->customer->name;
// Uma nova query é disparada para cada pedido
}Com 200 pedidos, esse trecho executa 201 queries no banco de dados. Com 2.000 pedidos, são 2.001 queries. O tempo de resposta cresce linearmente com os dados — e em algum momento a tela simplesmente para de carregar.
A solução: eager loading com with()
O Eloquent oferece o método with() para carregar os relacionamentos necessários em uma única query adicional, independentemente do tamanho da lista.
$orders = Order::with('customer')->get();
foreach ($orders as $order) {
echo $order->customer->name;
// Nenhuma query extra. Os dados já foram carregados.
}O resultado: sempre 2 queries, não importa quantos pedidos existam. Uma para os pedidos, uma para os clientes relacionados.
Carregando múltiplos relacionamentos
O with() aceita múltiplos relacionamentos e até aninhamento:
$orders = Order::with(['customer', 'items.product'])->get();Isso carrega pedidos, clientes e itens com seus produtos em apenas 3 queries.
Detectando N+1 em desenvolvimento
Configure o Laravel Debugbar ou adicione um listener no AppServiceProvider para capturar queries duplicadas durante o desenvolvimento:
// AppServiceProvider.php (somente em desenvolvimento)
if (app()->environment('local')) {
DB::listen(function ($query) {
\Log::info($query->sql, $query->bindings);
});
}Ou se quiser usar uma ferramenta externa, indico o What is LaraDumps? | LaraDumps
2. Complexidade O(n²): for dentro de for
Loops aninhados são intuitivos e fáceis de escrever. O problema é que eles escalam de forma quadrática: dobrar o volume de dados quadruplica o trabalho do servidor.
O problema:
$result = [];
foreach ($listA as $itemA) {
foreach ($listB as $itemB) { // O(n²)
if ($itemA->id === $itemB->ref_id) {
$result[] = $itemA;
}
}
}Com 100 itens em cada lista, são 10.000 comparações. Com 1.000 itens, são 1.000.000 comparações. Com 10.000, são 100.000.000. A função explode.
A solução: índice hash com keyBy()
A abordagem correta é transformar uma das listas em um mapa indexado por chave antes de iterar. Isso reduz a complexidade para O(n).
// Indexa $listB por 'ref_id' — custo O(n), feito uma vez
$indexed = collect($listB)->keyBy('ref_id');
foreach ($listA as $itemA) { // O(n)
if ($indexed->has($itemA->id)) {
$result[] = $itemA;
}
}A busca em um mapa hash é O(1) — constante, independente do tamanho da lista. O loop externo continua sendo O(n), mas o total permanece linear.
Preferindo operações de banco de dados
Sempre que possível, mova essa lógica para o banco de dados. Um JOIN ou whereIn com índice adequado é ordens de magnitude mais rápido que qualquer solução em PHP:
// Deixe o banco resolver a correlação entre as listas
$result = ModelA::whereIn('id', $listB->pluck('ref_id'))->get();3. Recursividade desnecessária: elegância com custo oculto
Recursividade é a ferramenta certa para problemas que se dividem naturalmente em subproblemas idênticos: percorrer árvores, processar estruturas hierárquicas, implementar algoritmos de divisão e conquista.
O problema está em usá-la onde um loop simples seria suficiente. Cada chamada recursiva empilha um frame na memória. Em listas grandes, isso consome RAM e pode estourar o limite de chamadas do PHP (xdebug.max_nesting_level).
function sumValues(array $items, int $index = 0): int
{
if ($index >= count($items)) {
return 0;
}
return $items[$index] + sumValues($items, $index + 1);
}Essa função percorre um array simples de forma recursiva, sem nenhuma necessidade. Para um array de 10.000 elementos, empilha 10.000 chamadas de função.
A solução: loop direto
function sumValues(array $items): int
{
return array_sum($items);
}Para casos mais complexos, um foreach ou array_reduce é sempre preferível à recursividade quando a estrutura de dados é plana:
function sumValues(array $items): int
{
$total = 0;
foreach ($items as $value) {
$total += $value;
}
return $total;
}Quando a recursividade é a escolha certa
Ela continua sendo a melhor ferramenta para estruturas genuinamente recursivas, como categorias com subcategorias ilimitadas:
function buildTree(Collection $categories, ?int $parentId = null): array
{
return $categories
->where('parent_id', $parentId)
->map(fn($category) => [
'id' => $category->id,
'name' => $category->name,
'children' => buildTree($categories, $category->id),
])
->values()
->all();
}Aqui a recursividade é justificada — a estrutura de dados é uma árvore. Para dados tabulares simples, não é.
Como criar o hábito de revisão
Identificar esses padrões isoladamente é relativamente simples. O desafio está em tornar a revisão de performance uma prática contínua da equipe, e não uma tarefa emergencial que surge após um incidente.
Algumas práticas que funcionam na prática:
Use o Telescope em desenvolvimento. O Laravel Telescope exibe todas as queries executadas por requisição, incluindo duplicatas. É o recurso mais rápido para identificar N+1 visualmente.
Estabeleça um limite de queries por rota. Defina internamente que rotas de listagem não devem ultrapassar, por exemplo, 10 queries. Se ultrapassar, entra no backlog.
Revise código com dados reais. Testes com 5 registros não revelam problemas de escala. Use seeds realistas (500, 5.000 registros) para expor gargalos antes do deploy.
Faça perguntas durante o code review. “O que acontece com esse código se essa tabela tiver 100.000 linhas?” é uma das perguntas mais valiosas que um revisor pode fazer.
Conclusão
Débito técnico de performance não se resolve com uma grande refatoração pontual. Ele se resolve com atenção contínua ao que já foi construído — não apenas ao que está sendo construído agora.
As três categorias apresentadas aqui — N+1, O(n²) e recursividade desnecessária — são responsáveis por uma parcela expressiva dos problemas de performance em aplicações Laravel que cresceram sem revisão. Cada uma tem solução conhecida, bem documentada e de implementação direta.
O que geralmente falta não é conhecimento técnico. É tempo reservado para olhar para trás.
Débito técnico não pago com atenção é pago com incidente.